OS-lab1
上机
1.lab1-exam:
在lab1课下分支的基础上,扩展printk函数,增加新的格式字符串"%[flags] [width] [length]R",从参数表中得到两个参数,两个参数当做“%[flags] [width] [length]d”输出,具体输出形式为"(参数1,参数2)“。例如printk(”%4R", 2023, 2023); 输出为"(2023,2023)"。只需要switch代码段增加一个case即可,类似两个case:d。记着输出完第一个参数,要把neg_flag归0。
1 | |
2.la1-extra
我们在lab1课下实现的printk是把格式字符串输出到终端,extra的目标是实现sprintf函数,把要输出的内容弄到缓冲区(就是到目标字符串buf),printk的原理为:调用vptintfmt解析fmt,真正的输出是把outputk函数(在vprintfmt传入output函数作为一个参数)。注意到vprintfmt第二个参数为NULL,在声明的时候第二个形参为void * data。第一个参数函数称为回调函数,第二个参数称为回调上下文,在printk并没有用到data。我们可以借助vprintfmt函数,第一个参数传入自定义的函数,第二个参数传入buf(当前缓冲区所在的位置)。我们要实现的自定义函数就是类似的outputk,只不过功能不是输出,而是把写入到当前缓冲区的位置,这时候你突然发现当前文件下memcpy函数已经实现了!!!为了可以一直更新data,我们只需要在所有需要缓冲的地方让data加上缓冲的字符串长度。还有一个小问题是,由于在vprintfmt函数中还调用了print_str, print_char, print_num在这三个函数中,为了把更新后的data传回vprintfmt,我把这三个函数的类型改为void*,然后返回值为更新后的data。需要注意在vprintfmt对data更新的时候,要先判断data是不是NULL,因为printk也会调用vprintfmt,但传入的data为NULL。其实要写的东西不多,仔细一点就好
1 | |
lab1思考题
一、Thinking
thinking1.1
x86交叉编译链:解决编译链程序和目标程序运行环境不同的问题,如在x86环境上使用编译工具进行编译汇编链接,而生成的程序需要运行在ARM开发板上
readelf:显示可执行程序的elf文件信息
objdump:显示程序信息,函数汇编等,常用于调试
objdump -h **.o 可查看目标文件的结构和内容
objdump -S 反汇编 -d可以16进制显示
LD(link script):主要是用来描述输入文件中的节(section)是如何映射到输出文件的,并且控制输出文件的内存布局(memory layout);源代码会编译成为目标对象文件(object file),每个对象文件中包含一系列的段(section),为LD的输入文件。
thinking1.2
发现在编译hello和readelf时的编译选项并不同
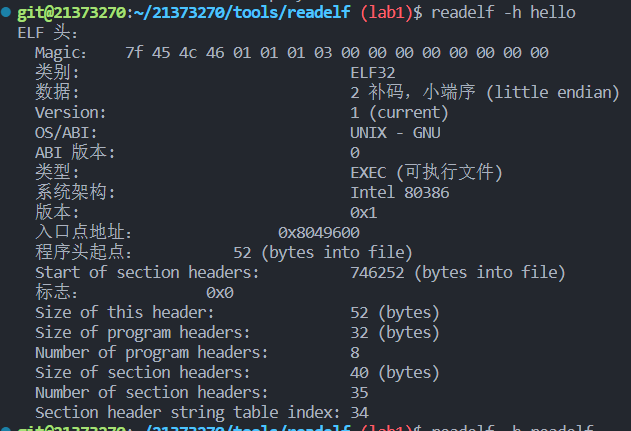
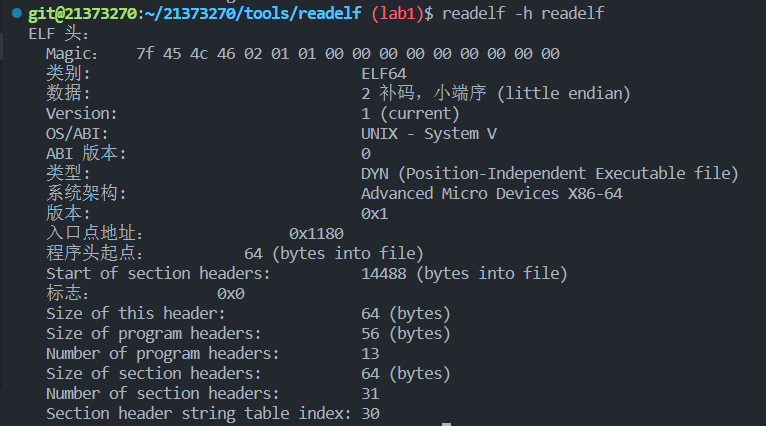
1.static:使用自带的readelf工具发现readelf文件类型为 DYN(Position-Independent Executable file),地址独立可执行文件,这是linux的一种保护方式,可以使程序在任意地址装载。hello则为简单的可执行文件,地址固定。
2.-32m:在我们的环境中,32位的程序运行的速度会更快,加上-32m选项,编译链接生成32位可执行程序,但是我们自己的readelf只能读64位。但是x86自带交叉编译工具readelf则可以读32位。
thinking1.3
启动分为两过程,硬件启动和软件启动,硬件启动的入口地址是由硬件决定的,之后才是我们内核也即软件启动,将ELF加载到内存中,此时内核入口由我们自定义的链接器决定。两个入口的含义是不一样的。
二、实验难点
1.理解我们内核镜像的结构
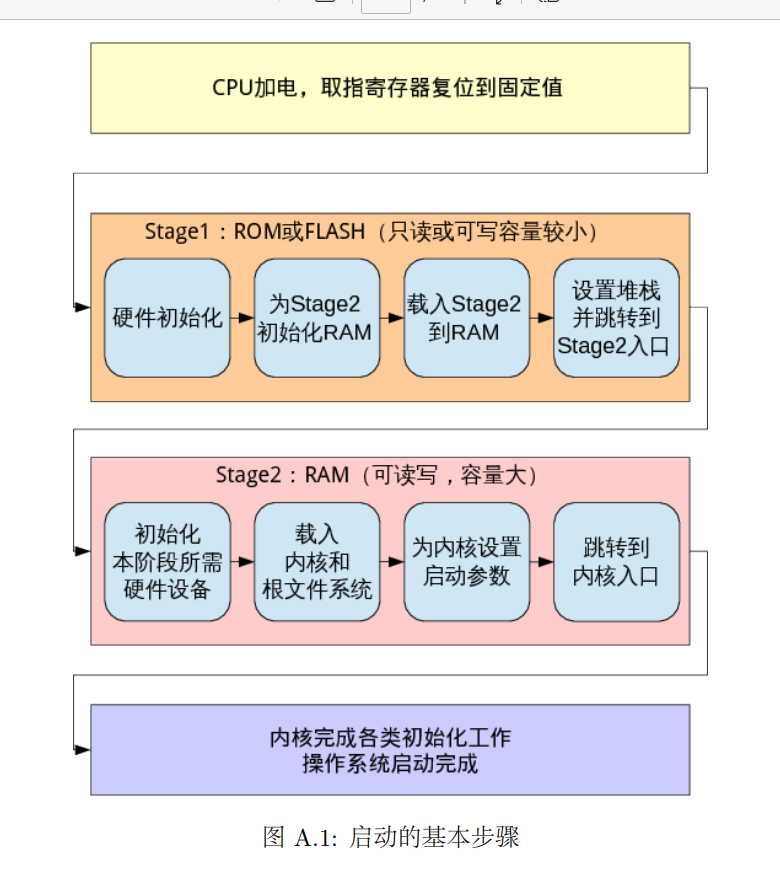
我们的开始是在stage2初始化CPU和内核栈,之后便调到init中的mips_init 函数用于初始化内核,我们在lab1中完成的仅仅是打印
2.readelf的补充
由ELF的文件地址计算节头表的地址时需要用 binary(const void *)如果用ehdr,ehdr + off,得到的是ehdr偏移ehdr大小的地址